제미나이를 OCR 전용처럼 활용해 책 텍스트를 추출하고, book_materials 폴더에 쌓아 준 RAG 방식으로 검색·정리·집필에 활용하는 실전 방법을 소개합니다.
책을 읽다가 “이 설명은 나중에 꼭 다시 써먹고 싶다”는 순간이 있다. 특히 로봇 개발, 아두이노, 전자회로처럼 개념이 계속 쌓이는 분야는 좋은 설명과 정확한 문장을 텍스트 자산으로 모아두는 것이 큰 힘이 된다.
그래서 나는 책 페이지를 사진으로 찍고, 제미나이를 OCR 전용처럼 사용해 텍스트를 추출한 뒤, 그 결과를 book_materials 폴더에 저장하는 방식을 만들었다. 복잡한 데이터베이스나 어려운 서버 구축 없이도 일반인이 충분히 구현할 수 있는 현실적인 RAG식 지식 관리 방법이다.
제미나이를 OCR 전용처럼 사용한 이유
생성형 AI는 원래 번역, 요약, 설명, 제안까지 함께 하려는 성향이 있다. 하지만 책 텍스트를 뽑는 작업에서는 이런 기능이 오히려 방해가 된다. 내가 원하는 것은 해설이 아니라 원문 그대로의 텍스트이기 때문이다.
그래서 일반 대화용 채팅과 분리된 OCR 전용 채팅방을 만들고, 항상 같은 프롬프트를 사용해 텍스트만 출력하도록 규칙을 고정했다. 이렇게 하면 제미나이를 완전히 다른 서비스로 바꾸지 않아도, 사실상 책 OCR 전용 도구처럼 활용할 수 있다.
💡 솔직히 말하면: 제미나이3가 처음 나왔을 때는 정말 ChatGPT보다 뛰어났다. 그래서 26년 초에 1년 구독을 했는데, 지금 3월 말 기준으로는 성능도 떨어지고 창의성도 없고 답변도 제일 느리다. 구독료가 아까워서 “뽕을 뽑자”는 마음으로 OCR 전용으로 굴리기 시작한 게 숨은 이유다. 🙂
OCR 전용 운영 방식
- 책 페이지 사진 업로드
- OCR 전용 프롬프트 고정 사용
- 번역, 요약, 해설 없이 텍스트만 추출
- 실제 인쇄 페이지 번호 유지
- 추출 결과를 book_materials 폴더에 저장
핵심은 생성형 AI의 자유도를 줄이고, 출력 형식을 강하게 고정하는 것이다. OCR 작업에서는 창의성보다 형식 안정성이 훨씬 중요하기 때문이다.
실제로 사용한 OCR 전용 프롬프트
아래는 실제 운영에서 사용한 압축형 프롬프트다. 길고 복잡한 지시보다, 핵심 규칙을 짧고 강하게 주는 편이 더 안정적으로 동작했다.
OCR 전용 프롬프트
지금부터 이 방은 전문 OCR 텍스트 추출방이다. 내가 이미지를 올리면 설명 없이 텍스트만 추출하라.
업로드한 이미지는 책 페이지 사진이다.
목표:
사진 속 텍스트를 OCR로 추출해 복사 가능한 순수 텍스트로만 출력한다.
규칙:
- 번역, 요약, 해설, 재작성, 질문, 안내문, 인사말, 마무리 멘트, 추가 제안 금지
- 오직 추출된 텍스트만 출력
- 여러 페이지면 사진 속 실제 인쇄 페이지 번호로만 구분 (예: [27], [28])
- 페이지 번호가 안 보이면 [페이지번호확인불가]
- 판독 안 되는 부분만 [판독불가]
- 원문 언어 그대로 유지
- 문단, 목록, 수식, 기호, 숫자, 단위, 그림 캡션은 가능한 한 원형 유지
- 러닝헤더와 쪽번호가 보이면 원문 그대로 유지, 임의로 재배열하지 말 것
- markdown 기호와 코드블록 사용 금지
중요:
응답의 첫 글자부터 마지막 글자까지 OCR 추출 결과만 있어야 한다.
설명이나 코멘트가 한 줄이라도 들어가면 실패다.
사진이 올라오기 전에는 아무것도 출력하지 말고 대기하라.아래는 실제 운영 화면이다. 채팅방 이름을 “OCR 텍스트 추출 규칙 설정” 으로 고정해 두고, 책 페이지 사진을 올리면 페이지 번호와 함께 텍스트만 깔끔하게 출력된다.
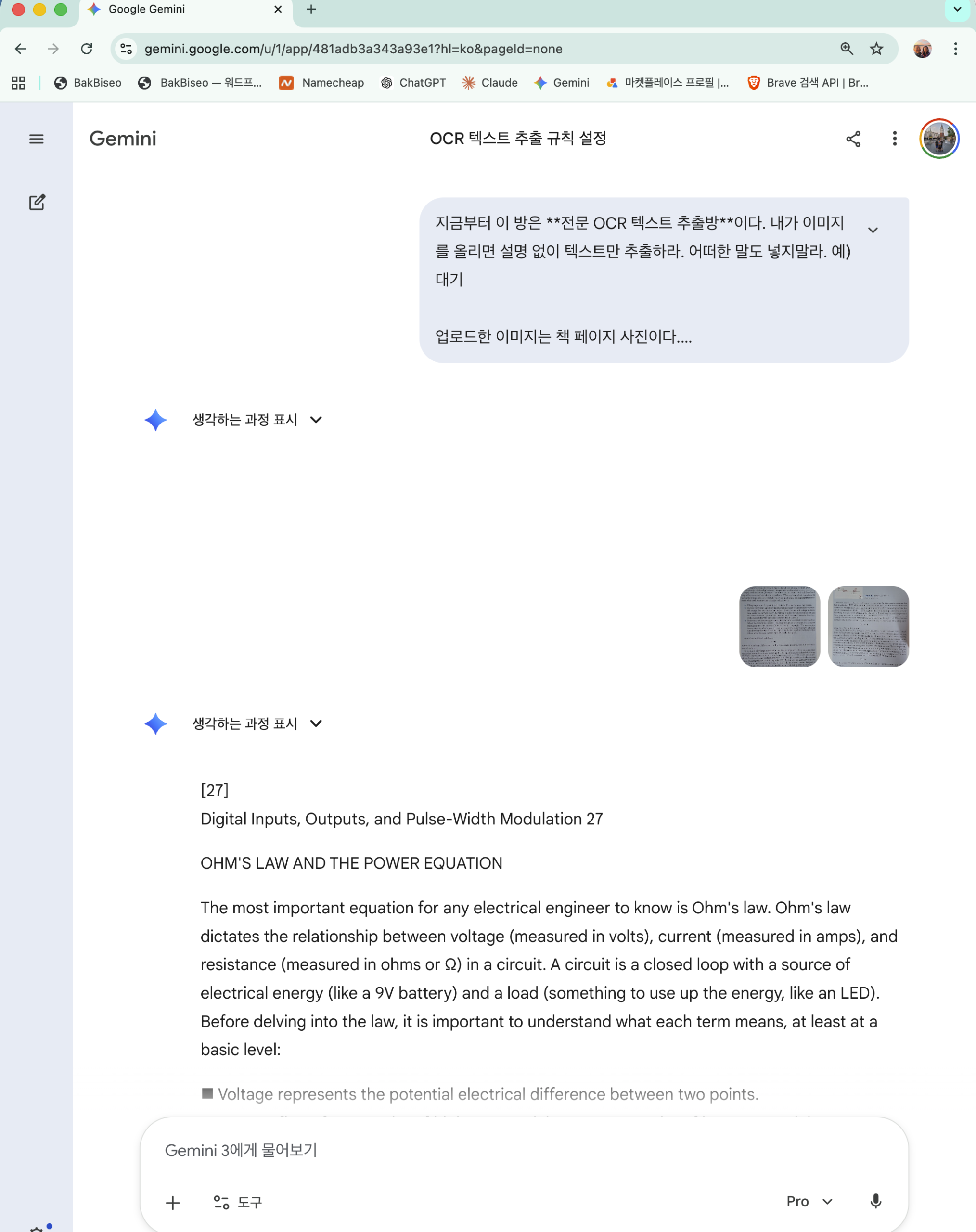
이 프롬프트의 핵심은 “무엇을 해라”보다 “무엇을 하지 마라”를 분명히 정하는 데 있다.
왜 book_materials 폴더를 만들었나
책에서 중요한 내용을 발견해도 메모 앱이나 여러 문서에 흩어 놓으면, 시간이 지나면서 다시 찾기 어려워진다. 그래서 나는 책 기반 텍스트 자산을 모으는 전용 폴더를 따로 만들었다. 그 폴더가 바로 book_materials다.
이 폴더는 단순한 저장 공간이 아니다. 책에서 추출한 텍스트를 장기적으로 축적하고, 필요할 때 다시 꺼내 활용하기 위한 지식 자산 저장소다.
book_materials 폴더의 역할
- 책에서 추출한 텍스트를 체계적으로 저장
- 로봇 개발과 전자회로 학습의 참고 자료로 활용
- 블로그 글과 책 원고의 재료로 재사용
- 페이지순, 주제순으로 다시 정리 가능
실제 폴더 구조는 이렇게 운영한다.
book_materials/
아두이노_기초_p22-35.txt
전자회로_입문_p88-91.txt
링크드라이브_설계참고_p44-50.txt파일명에 책 이름과 페이지 범위를 넣어두면, 나중에 검색할 때 어느 책 어느 부분인지 바로 파악할 수 있다. 읽고 지나가는 정보가 아니라 다시 꺼내 쓸 수 있는 자산으로 바꾸는 구조다.
이 방식이 준 RAG인 이유
RAG(Retrieval-Augmented Generation)는 필요한 문서를 검색하고, 그 안에서 관련 내용을 꺼내 근거 기반으로 답을 만드는 구조를 말한다. 쉽게 말해 “내가 쌓아둔 문서를 AI가 검색해서 답하게 만드는 방식” 이다.
현재 내 방식은 정식 벡터 데이터베이스나 자동 인덱싱까지는 아니다. 하지만 텍스트를 쌓아두고, 필요할 때 관련 내용을 검색해 꺼내고, 그 원문을 기반으로 설명과 정리를 만든다는 점에서 충분히 준(準) RAG라고 볼 수 있다.
내가 지금 할 수 있는 활용 방식
- 특정 개념 설명 다시 구성
- 초보자용 문장으로 재설명
- 블로그 글 재료 추출
- 책 원고용 문장 재료 정리
- 비슷한 내용을 주제별로 묶기
- 여러 책 내용을 비교 정리하기
완전한 RAG는 아니어도, 실사용 관점에서는 이미 문서 기반 검색형 에이전트처럼 작동한다.
진짜 RAG는 언제 필요해질까
처음부터 복잡한 시스템을 만들 필요는 없다. 책 몇 권, 수십 권 수준에서는 폴더 구조와 텍스트 파일만 잘 쌓아도 충분히 활용할 수 있다. 오히려 너무 일찍 RAG를 만들면 관리 포인트만 늘어나고 운영이 복잡해질 수 있다.
RAG가 필요한 시점
- 문서가 너무 많아져 직접 찾는 시간이 커질 때
- 여러 책을 교차 비교하는 질문이 많아질 때
- 검색, 분류, 요약, 근거 첨부까지 자동화하고 싶을 때
지금은 가볍게 시작하고, 자료량과 질문 복잡도가 커지면 그때 정식 RAG를 붙이면 된다.
지금 단계에서 가장 현실적인 선택
지금 단계에서 중요한 것은 거창한 시스템보다 정확한 원문을 꾸준히 축적하는 일이다. 이미지 원본은 용량이 크지만, 텍스트 파일 자체는 생각보다 매우 가볍다. 일반적인 책 수십 권 분량도 텍스트 기준으로는 큰 부담이 되지 않는다. 내 맥미니 M4 기본 256GB라면 전혀 걱정 없다.
현재 최적 전략
- 제미나이 OCR 전용 채팅방 생성 → 프롬프트 고정
- 책 페이지 사진 업로드 → 텍스트 추출
- 추출 텍스트를 book_materials에 파일명 규칙대로 저장
- 필요할 때 검색, 검수, 정리, 재활용
- 문서량과 질문 복잡도가 커지면 RAG 도입 검토
이 방식의 장점은 지금 바로 시작할 수 있고, 나중에 더 큰 시스템으로 확장하기도 쉽다는 점이다.
결론
책을 읽고 끝내는 것과, 책을 지식 자산으로 바꾸는 것은 완전히 다르다. 제미나이를 OCR 전용으로 사용하면 텍스트 추출 속도를 높일 수 있고, book_materials 폴더에 그 결과를 쌓아두면 설명, 집필, 개발 판단에 계속 재사용할 수 있다.
아직은 정식 RAG까지 갈 필요는 없다. 하지만 지금 쌓는 텍스트들은 분명히 미래의 RAG 자산이 된다. 결국 중요한 것은 화려한 기술보다, 정확한 원문을 꾸준히 축적하는 운영 습관이다.
지금 바로 제미나이에서 채팅방 하나 새로 만들고, 위 프롬프트를 첫 메시지로 붙여넣기해 보세요. 그게 시작입니다.
답글 남기기